$mathrmWojood^Relations$: Arabic Relation Extraction Corpus and Modeling
Abstract
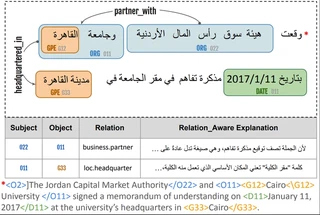
Relation extraction (RE) is a core task in natural language processing, crucial for semantic understanding, knowledge graph construction, and enhancing downstream applications. Existing work on Arabic RE remains limited due to the language′s rich morphology and syntactic complexity, and the lack of large, high-quality datasets. In this paper, we present $mathrmWojood^Relations$, the largest and most diverse Arabic RE corpus to date, containing over $33K$ sentences ($∼550K$ tokens) annotated with $∼15K$ relation triples across 40 relation types. The corpus is built on top of Wojood NER dataset with manual relation annotations carried out by expert annotators, achieving a Cohen′s $ąppa$ of 0.92, indicating high reliability. In addition, we propose two methods: NLI-RE, which formulates RE as a binary natural language inference problem using relation-aware templates, and GPT-Joint, a few-shot LLM framework for joint entity and RE via relation-aware retrieval. Finally, we benchmark the dataset using both supervised models and in-context learning with LLMs. Supervised models achieve 92.89% F1 for RE, while LLMs obtain 72.73% F1 for joint entity and RE. These results establish strong baselines, highlight key challenges, and provide a foundation for advancing Arabic RE research.
Type
Publication
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing